R使用HBase
前言
目前数据科学与商业智能领域有三点不容忽视的趋势:一是集群化,随着数据量不断增长,越来越多的分析工作需要依赖于Hadoop、Spark等集群进行;二是Web化,随着数据科学工作人员整体素质的不断提高,对于分析实验的可重复性、可分享性越来越看中,很多数据分析师已经转变工作方式,开始基于Markdown记录实验文档,并将成果转化为Web分享给大家,典型例子有rmarkdown、shiny、jupyter notebook等;三是NoSQL化,传统数据库在海量数据前越来越吃力,集群的块存储模型读取过慢,NoSQL对于需要频繁交互与跟踪的数据分析任务变得很重要。
本文将要介绍的HBase依赖于Hadoop集群,是NoSQL中的典范。R语言通过Revolution Analytics提供的rhbase包可以方便地和HBase进行交互,再结合shiny可以快速地搭建一个数据分析的可视化工具。本文使用的例子对上面提到的三点趋势提供了很好的佐证。
环境准备
首先,按照官方教程安装配置HBase。
然后,按照这篇文章安装Thrift。注意需要安装C++的Library,因为rhbase依赖于它,建议安装Thrift 0.8.0版本。
启动HBase的Thrift服务:bin/hbase-daemon.sh start thrift。
按照RHadoop官方教程安装rhbase。
rhbase基础
rhbase的文档案例写的很清楚,阅读一遍即可知道rhbase的使用方法。
library(rhbase)
hb.init()
hb.new.table('testtable','x','y','z')
hb.describe.table('testtable')
# Not required to labels to be 'family:label', can just provide 'family'
# which is equivalent to 'family:'
hb.insert("testtable",list(list("20100101",c("x:a","x:f","y","y:w"), list("James Dewey",TRUE, 187.5,189000))))
hb.insert("testtable",list(list("20100102",c("x:a"), list("James Agnew"))))
hb.insert("testtable",list(list("20100103",c("y:a","y:w"), list("Dilbert Ashford",250000))))
hb.insert("testtable",list(list("20100104",c("x:f"), list("Henry Higs"))))
hb.get("testtable",list("20100101","20100102"))
hb.get("testtable",list("20100101","20100102"),c("y")) # columns that start with y
hb.get("testtable",list("20100101","20100102"),c("y:w"))
hb.get("testtable",list("20100101","20100102"),c("y:w","z"))
# delete
hb.delete("testtable","20100103","y:a")
hb.get("testtable","20100103")
## will not get 20100103, since no 'x'
iter <- hb.scan("testtable",startrow="20100100",colspec="x")
while( length(row <- iter$get(1))>0){
print(row)
}
iter$close()
# scan from beginning
iter <- hb.scan("testtable",startrow="20100100",colspec=c('x','y','z'))
while( length(row <- iter$get(1))>0){
print(row)
}
iter$close()
# scan uptil 20100103 (not including it)
iter <- hb.scan("testtable",startrow="20100100",end="20100103",colspec=c('x','y','z'))
while( length(row <- iter$get(1))>0){
print(row)
}
iter$close()
# Insert a data frame
x <- data.frame(x=c("Winston","Jen","Jasmine"), y=runif(3),z=c(1,2,3))
rownames(x) <- c("20100105","20100106","20100107")
colnames(x) <- c("x:x", "y:y", "z:z")
hb.insert.data.frame("testtable",x)
# get data frame, note the columns have ":" appended
iter <- hb.get.data.frame("testtable",start="20100105")
iter()
# Uptil penultimate row
iter <- hb.get.data.frame("testtable",start="20100105",end="20100107")
iter()
# clean up
hb.delete.table("testtable")rhbase有三种序列化的方式,一种是R的native模式,一种是raw模式(即一堆字节码),一种是character模式。如果表数据的写入和读取都只用R,建议用native模式(这也是默认模式)。如果数据读取或写入还需要别的语言,建议用raw或character。不考虑存储空间,为了方便人读取,使用character模式最方便。设置序列化的方法如下:
hb.init(host="127.0.0.1", port=9090, serialize = "character")rhbase与shiny结合
本节提供一个rhbase与shiny结合的一个案例:根据道路编号与日期,查询道路某一天的24小时通车数曲线;根据道路编号与日期范围,查询道路在这段日期范围内的每日通车数。
我们首先需要建立一张HBase表,表的规格设置如下:
| 字段 | 描述 |
|---|---|
row_key |
HBase表的键,格式为道路编号_日期 |
link:tc |
HBase表的列,列族为link,列为tc,表示row_key对应的日通车数 |
link:tc_10m |
HBase表的列,列族为link,列为tc_10m,表示row_key对应的这一天这一条道路每10分钟的通车数,按照时间排序,共144个,格式为[通车数1,通车数2,...] |
可视化工具的代码如下:
library(rhbase)
library(stringr)
library(jsonlite)
library(lubridate)
library(xts)
library(dygraphs)
library(shiny)
library(tidyr)
library(dplyr)
# init
hb.init(host="127.0.0.1", port=9090, serialize="character")
hb.list.tables()
table_name <- "test"
hb.describe.table(table_name)
ui <- fluidPage(
titlePanel("Traffic Flow Viewer"),
hr(),
h3("Link flow plot per 10 min"),
sidebarLayout(
sidebarPanel(
textInput(inputId = "link", label = "Link:", value="xxxx, lllll, oooo "),
dateInput(inputId = "dt_10m", label = "Date:", value="2016-12-05"),
width=3
),
mainPanel(
textOutput(outputId = "text_10m"),
dygraphOutput(outputId = "plot_10m"),
width=9
)
),
hr(),
h3("Link flow plot per day"),
sidebarLayout(
sidebarPanel(
dateRangeInput(inputId = "dt_day", label = "Date Range:", start="2016-11-26", end="2016-12-06"),
width=3
),
mainPanel(
dygraphOutput(outputId = "plot_day"),
width=9
)
)
)
server <- function(input, output, session) {
get_link_flow <- reactive({
row_key <- str_c(str_trim(unlist(str_split(input$link, ","))), as.character(input$dt_10m, format="%Y%m%d"), sep="_")
return(hb.get(table_name, as.list(row_key), c('link:tc_10m')))
})
batch_get_link_flow <- reactive({
links <- str_trim(unlist(str_split(input$link, ",")))
dts <- as.character(seq(as.POSIXct(input$dt_day[1]),as.POSIXct(input$dt_day[2]), by="1 day"), format="%Y%m%d")
row_key <- (tidyr::unite(expand.grid(link=links, dt=dts), row_key, link, dt))$row_key
# row_key <- setNames(split(comb_df, seq(nrow(comb_df))), NULL)
return(hb.get(table_name, as.list(row_key), c('link:tc')))
})
output$plot_10m <- renderDygraph({
if(input$link != "" && !is.na(input$link)) {
link_flow <- get_link_flow()
if(length(link_flow[[1]][[3]]) >= 1) {
obs_df <- NULL
for(i in 1:length(link_flow)) {
obs_link <- str_split(link_flow[[i]][[1]], "_")[[1]][1]
obs_dt <- str_split(link_flow[[i]][[1]], "_")[[1]][2]
obs_flow <- data.frame(cnt=fromJSON(link_flow[[i]][[3]][[1]]))
colnames(obs_flow) <- c(obs_link)
if(is.null(obs_df)) {
obs_df <- obs_flow
}
else {
obs_df <- cbind(obs_df, obs_flow)
}
}
dt_point <- ymd(obs_dt, tz="Asia/Shanghai") + dseconds(1:nrow(obs_flow) * 600)
rownames(obs_df) <- dt_point
dygraph(as.xts(obs_df)) %>%
dyOptions(drawPoints = TRUE, pointSize = 2)
}
}
})
output$plot_day <- renderDygraph({
if(input$link != "" && !is.na(input$link)) {
link_flow <- batch_get_link_flow()
obs_df <- data.frame()
for(i in 1:length(link_flow)) {
if(length(link_flow[[i]][[3]]) >= 1) {
obs_link <- str_split(link_flow[[i]][[1]], "_")[[1]][1]
obs_dt <- ymd(str_split(link_flow[[i]][[1]], "_")[[1]][2])
obs_flow <- as.integer(link_flow[[i]][[3]][[1]])
obs_df <- rbind(obs_df, data.frame(link_id=obs_link, dt=obs_dt, cnt=obs_flow))
}
}
obs_df <- obs_df %>% spread(link_id, cnt)
rownames(obs_df) <- ymd(obs_df$dt)
obs_df <- obs_df %>% select(-dt)
dygraph(as.xts(obs_df)) %>%
dyOptions(drawPoints = TRUE, pointSize = 2) %>%
dyRangeSelector()
}
})
output$text_10m <- renderText({
if(input$link != "" && !is.na(input$link)) {
link_flow <- get_link_flow()
if(length(link_flow[[1]][[3]]) >= 1) {
"The 10 min flow plot is below:"
}
else {
"Row key could not be found"
}
}
else {
"Please specify the link"
}
})
}
shinyApp(ui=ui, server=server)效果图如下:
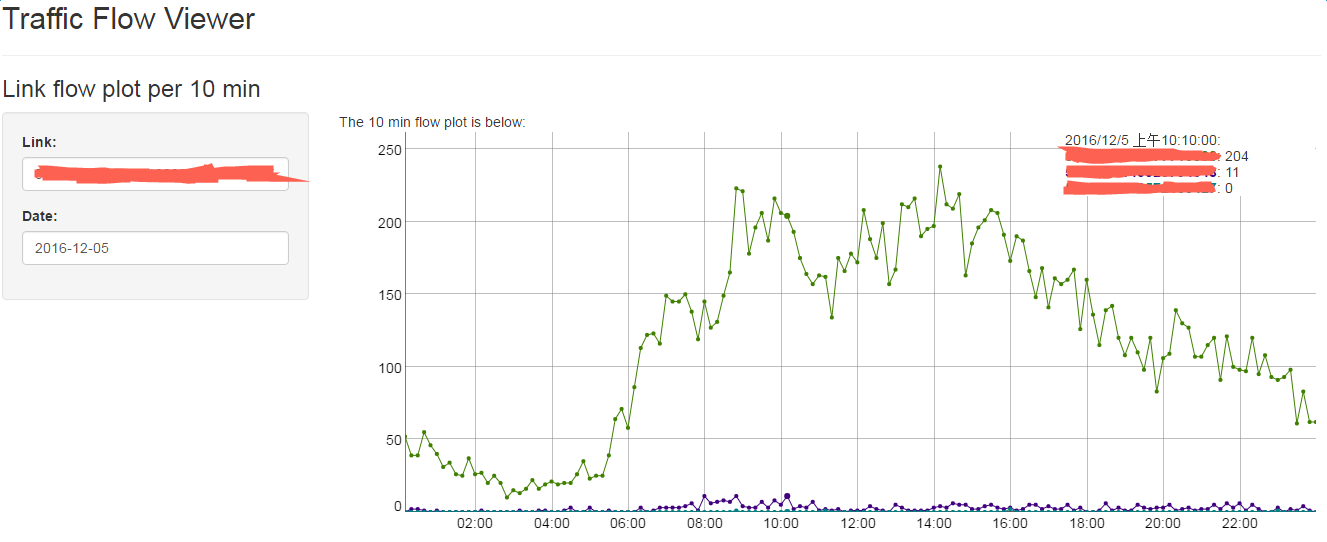
10分钟流量曲线
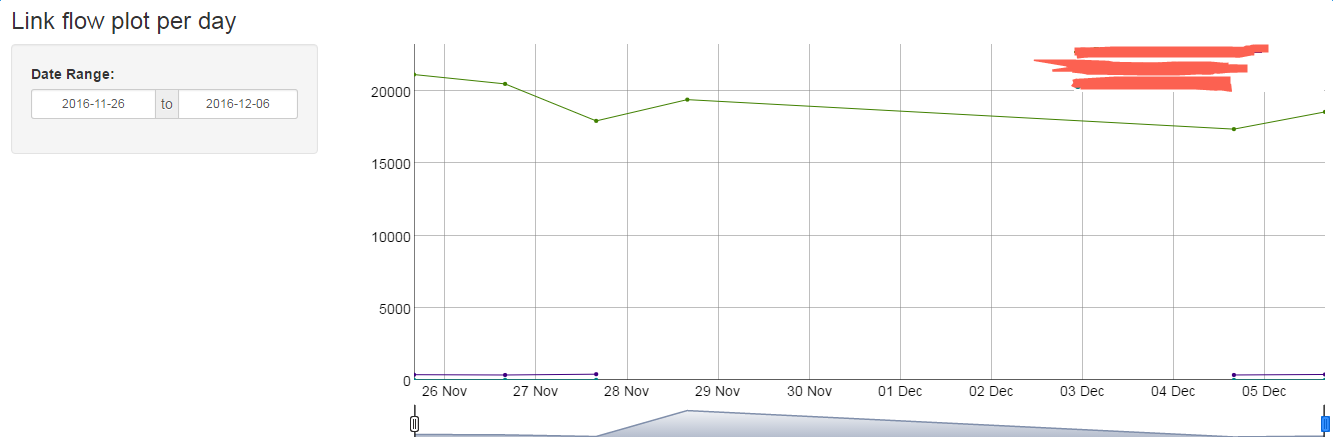
每日流量曲线