numpy ndarray详解
前言
如果没有numpy,Python内部只能用list或array来表示矩阵。假如用list来表示[1,2,3],由于list的元素可以是任何对象,因此list中所保存的是对象的指针,这样就需要有3个指针和三个整数对象,比较浪费内存和CPU计算时间。Python的array和list不同,它直接保存数值,和C语言的一维数组比较类似,但是不支持多维,表达形式很简陋,写科学计算的算法很难受。numpy弥补了这些不足,核心贡献就是提供了ndarray这个存储单一数据类型的多维数组结构,实现上采用预编译好的C语言代码,性能上的表现十分不错。
ndarray内存结构
使用下面的代码可以生成本文讲解的ndarray案例:
from numpy import np
a = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32)我们来看一下ndarray如何在内存中储存的:关于数组的描述信息保存在一个数据结构中,这个结构引用两个对象,一块用于保存数据的存储区域和一个用于描述元素类型的dtype对象。
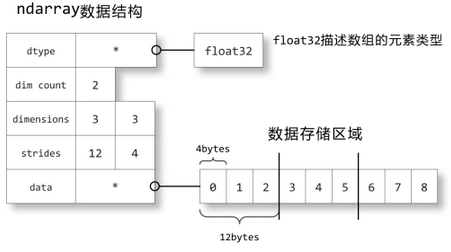
数据存储区域保存着数组中所有元素的二进制数据,dtype对象则知道如何将元素的二进制数据转换为可用的值。数组的维数、大小等信息都保存在ndarray数组对象的数据结构中。
strides中保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数。例如图中的strides为12,4,即第0轴的下标增加1时,数据的地址增加12个字节:即a[1,0]的地址比a[0,0]的地址要高12个字节,正好是3个单精度浮点数的总字节数;第1轴下标增加1时,数据的地址增加4个字节,正好是单精度浮点数的字节数。
深入dtype
Python内置的基本数据类型,每个类别只有一种,比如只有一种整数int,只有一种浮点数float。对于不需要关心计算机如何存储数据的应用,只提供一种选择是非常方便的。但是对于科学计算而言,这是不够的,为了性能和精度往往需要根据具体场景控制更多的细节。为此,NumPy内置了24种基本类型,基本上可以和C语言的数据类型对应上,其中部分类型对应为Python内置的类型。下表列举了常用NumPy基本类型。
| 类型 | 注释 |
|---|---|
bool_ |
兼容Python内置的bool类型 |
bool8 |
8位布尔 |
int_ |
兼容Python内置的int类型 |
int8 |
8位整数 |
int16 |
16位整数 |
int32 |
32位整数 |
int64 |
64位整数 |
uint8 |
无符号8位整数 |
uint16 |
无符号16位整数 |
uint32 |
无符号32位整数 |
uint64 |
无符号64位整数 |
float_ |
兼容Python内置的float类型 |
float16 |
16位浮点数 |
float32 |
32位浮点数 |
float64 |
64位浮点数 |
str_ |
兼容Python内置的str类型 |
24个scalar types并不是dtype,但是可以作为参数传递给np.dtype()构造函数产生一个dtype对象,如np.dtype(np.int32)。在NumPy中所有需要dtype作为参数的函数都可以使用scalar types代替,会自动转化为对应的dtype类型。
Structured Array
由于numpy只支持单一数据类型,对于常见的表格型数据,我们需要通过numpy提供的Structrued Array机制自定义dtype。
定义结构化数组有四种方式:1) string, 2) tuple, 3) list, or 4) dictionary。本文推荐使用后两种方式。
import numpy as np
# list方式:a list of tuples. Each tuple has 2 or 3 elements specifying: 1) The name of the field (‘’ is permitted), 2) the type of the field, and 3) the shape (optional)
persontype = [('name', np.str_), ('age', np.int16), ('weight', np.float32)]
# dict方式:需要指定的键值有names和formats
persontype = np.dtype({
'names': ['name', 'age', 'weight'],
'formats': [np.str_, np.int16, np.float32]
})
a = np.array([("Zhang", 32, 75.5), ("Wang", 24, 65.2)], dtype=persontype)
创建ndarray
共有三类基本方法:一是从Python内置的array-like数据结构转化得到;二是利用numpy提供的创建函数直接生成;三是使用genfromtxt()方法生成。
# -*- coding: utf-8 -*-
import numpy as np
# 从python的list转换
x = np.array([[1,2.0],[0,0],(1+1j,3.)])
np.zeros((2, 3))
np.arange(2, 3, 0.1) # start, end, step
np.linspace(1., 4., 6) # start, end, num
np.indices((3, 3)) # 返回一个array,元素0是行下标,元素1是列下标;行下标为一个3*3二维array,对应3*3矩阵的行下标;列下标为一个3*3二维array,对应3*3矩阵的列下标
ndtype=[('a',int), ('b', float), ('c', int)]
names = ["A", "B", "C"]
np.genfromtxt("file_name.txt",
delimiter=",",
names=names,
dtype=ndtype,
autostrip=True,
comments="#",
skip_header=3,
skip_footer=5,
usecols=(0, -1))
# ndarray to list
a = np.array([[1, 2], [3, 4]])
a.tolist()索引
ndarray索引的基本使用方法示例如下;
x = np.arange(10)
x.shape = (2,5)
x[0][2]
x[:,0:5:2]
关于ndarray的索引方式,有以下几个重点需要记住:
- 虽然
x[0,2] = x[0][2],但是前者效率比后者高,因为后者在应用第一个索引后需要先创建一个temporary array,然后再应用第二个索引,最后找到目标值。 - 分片操作不会引发copy操作,而是创建原ndarray的view;他们所指向的内存是同一片区域,无论是修改原ndarray还是修改view,都会同时改变二者的值。
- index array和boolean index返回的是copy,不是view。
关于上面列举的分片操作不会引发copy操作,我们来进一步探讨一下。先看一下numpy的例子:
import numpy as np
a = np.arange(10)
a.shape = (2,5)
print "input a:", a
b = a[0, ]
print "copy b:", b
b[1] = -1
print "modify b:", b
print "final a:", a ## input a: [[0 1 2 3 4]
## [5 6 7 8 9]]
## copy b: [0 1 2 3 4]
## modify b: [ 0 -1 2 3 4]
## final a: [[ 0 -1 2 3 4]
## [ 5 6 7 8 9]]再来看一下R的例子:
a <- matrix(0:9, nrow=2, byrow=TRUE)
a## [,1] [,2] [,3] [,4] [,5]
## [1,] 0 1 2 3 4
## [2,] 5 6 7 8 9b <- a[1,]
b[2] <- -1
b## [1] 0 -1 2 3 4a## [,1] [,2] [,3] [,4] [,5]
## [1,] 0 1 2 3 4
## [2,] 5 6 7 8 9可以看到numpy和R在矩阵的分片操作有不同的设计理念:在R里分片操作会引起数据的复制,在numpy里不会。事实上,R的设计理念很多时候可以用一句话来概括:copy on modify,一旦对数据有修改就会引起内存上的复制操作,这个操作要花不少时间,因此经常会听到人们抱怨R费内存且速度慢。所以,我们可以看到numpy在处理这件事情上明显要用心很多,根据场景设计了不同的策略,不是简单地采用R的一刀切方式。当然,这也带来了一些学习成本,需要对numpy足够熟悉才能避免踩坑。R社区里对copy on modify的哲学也有诟病并在努力改变,比如同是data.frame操作库的data.table和dplyr,data.table性能比dplyr高很多,部分原因也是data.table规避了copy on modify的方式。
再来看一下Structured Array的索引效率。
import numpy as np
import time
persontype = [('name', np.str_), ('age', np.int16), ('weight', np.float32)]
a = np.array([("Zhang", 32, 75.5), ("Wang", 24, 65.2)], dtype=persontype)
start = time.clock()
a[1]
end = time.clock()
print "a[1] cost time: %f" % (end-start)
start = time.clock()
a['name']
end = time.clock()
print "a['name'] cost time: %f" % (end-start)
start = time.clock()
a[1]['name']
end = time.clock()
print "a[1]['name'] cost time: %f" % (end-start)
start = time.clock()
a['name'][1]
end = time.clock()
print "a['name'][1] cost time: %f" % (end-start)## a[1] cost time: 0.000006
## a['name'] cost time: 0.000020
## a[1]['name'] cost time: 0.000037
## a['name'][1] cost time: 0.000002从上面的结果,我们发现,获取相同的数据有多种操作,不同的操作性能差别很大。我做了一个推测,纯粹是瞎猜:numpy在建立结构化数组时,将整个结构体连续存储在一起,即按行存储,因此a[1]的速度最快;但是为了保证提取列的效率,对a['name']建立了索引,因此a['name']的效率也很高;但是这个索引只对整个a起作用,如果输入只有a的一部分,仍然需要遍历整个a,去提取出对应的数据,因此a[1]['name']比a['name'][1]的效率差很多。
参考文献