R读写Excel
前言
Excel是数据分析师最常用的工具之一,相比其他数据分析工具有自己无可替代的一些特性,特别是在交互式分析这种强依赖分析师思维与创意的工作中特别奏效。但是,Excel的缺点也很明显:不适合做重复性比较高的工作。可重复性是科学研究的重要标准,我们作为有学院做派的数据分析师,只依赖Excel是不够的,还需要掌握一门python或R这样的编程语言。那么在不同的工具之间进行数据的相互转换,变成了数据分析师的一个基本能力。
本文讲解R和Excel的数据转换工具集,主要使用以下两个包:
install.packages(c("xlsx", "readxl"))Read Excel
R读写Excel有许多包提供了解决方案,其中基于Java有一个很成熟的方案:xlsx。这个包提供了两套读写Excel的工具函数:read.xlsx,read.xlsx2,write.xlsx,write.xlsx2。此外,xlsx在输出Excel时还提供了控制文件格式的功能函数集,可以按照要求生成图文并茂的Excel分析报告。下图从这里取来,很好地诠释了xlsx的核心功能。本文只介绍使用频度最大的数据读写功能。
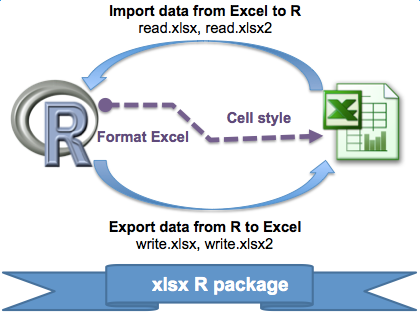
read.xlsx在读取Excel时,会自动推测每个字段的类型,但效率较低,适合读取小数据集;read.xlsx2更多地依赖Java实现功能,因此读取效率高,但是每个字段的类型需要用户自行指定,否则全部当做字符串character处理,默认转化为factor类型。另外,read.xlsx读取中文时需要显示指定编码方式,否则会变为乱码;read.xlsx2不需要。
library("xlsx")
file <- system.file("tests", "test_import.xlsx", package = "xlsx")
res <- read.xlsx(file, 1, encoding="UTF-8") # 需要指定读取的Sheet编号或者名称,中文需要指定编码
str(res)
res2 <- read.xlsx2(file, 1, stringsAsFactors=FALSE) # 将字符串按照字符串处理
str(res2)
res3 <- read.xlsx2(file, 1, colClasses=c("character", rep("numeric", ncol(res2) - 1))) # 显示指定每个字段的类型,字符串会被转变为factor
str(res3)在读取Excel数据时,一个很重要的问题是对日期时间datetime类型的处理。从微软官方文档,我们知道Excel处理日期时间的底层逻辑是:
Excel 将所有日期存储为整数,将所有时间存储为小数。有了此系统,Excel 可以像处理任何其他数字一样对日期和时间进行加、减或比较操作,而且所有的日期都可以使用此系统进行处理。在此系统中,序数 1 代表 1/1/1900 12:00:00 a.m.。时间存储为 .0 到 .99999 之间的小数,其中 .0 为 00:00:00,.99999 为 23:59:59。日期整数和时间小数可以组合在一起,生成既有小数部分又有整数部分的数字。例如,数字 32331.06 代表的日期和时间为 7/7/1988 1:26:24 a.m.。
而一般的编程语言采用的是Unix时间戳,即距离1970-01-01 00:00:00 GMT的秒数。
我们来看一下这两套系统的原点差了多少天:
# 此处只为演示两个系统换算方法的推演过程,关于lubridate包的使用请参考本系列日期时间专题文章
library(lubridate)
span <- interval(start=ymd("1900-01-01", tz="GMT"), end=ymd("1970-01-02", tz="GMT")) # 时间段为前闭后开区间,即[1900-01-01, 1970-01-02)
span / ddays(1) + 1 # 相差天数,加1的原因是微软的原点取值为1,Unix时间戳的原点设置为0.## [1] 25569所以读取Excel时转化日期的方法如下:
# To convert an Excel datetime colum to POSIXct, do something like:
# as.POSIXct((x-25569)*86400, tz="GMT", origin="1970-01-01")
# For Dates, use a conversion like:
# as.Date(x-25569, origin="1970-01-01") 注:POSIXct是R日期时间的一种类型;Excel中的日期没有时区的概念,都是GMT时间。所以在调用as.POSIXct指定时区的时候要使用GMT。xlsx的官方文档描述如下:
Excel internally stores dates and datetimes as numeric values, and does not keep track of time zones and DST. When a datetime column is brought into R, it is converted to POSIXct class with a GMT timezone. Occasional rounding errors may appear and the R and Excel string representation my differ by one second. For read.xlsx2 bring in a datetime column as a numeric one and then convert to class POSIXct or Date.
在读取Excel方面,xlsx用起来还是有些不方便,需要考虑性能选择不同的函数、是否自己提供每列的类型、中文编码、日期时间转换等问题。R语言的泰斗Hadley Wickham领头制作的readxl包提供了一个更优雅的解决方案。这个方案基于C和C++实现,安装时不需要依赖外部环境,所以很容易安装使用。在读取Excel方面,它的性能明显优于xlsx。此外,它会将non-ASCII的字符(包括中文)自动重新编码为UTF-8,解决乱码的困扰;自动将日期时间转化为POSIXct类型,且支持Windows(1900)和Max(1904)两个平台,让用户无需了解Excel底层日期时间的原理就可以正确使用。
library(readxl)
datasets <- system.file("extdata/datasets.xlsx", package = "readxl")
res4 <- read_excel(datasets)
str(res4)## Classes 'tbl_df', 'tbl' and 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : chr "setosa" "setosa" "setosa" "setosa" ...Write Excel
xlsx提供了两个函数实现将R的data.frame写出为Excel。write.xlsx的实现依赖于xlsx对每个单元格单独定制处理的底层机制,对data.frame进行两层循环,逐个元素写入到Excel的单元格,性能较低。write.xlsx2的实现依赖于xlsx对一个矩形范围的单元格统一定制处理的底层机制,一次性将data.frame写入到Excel的Sheet中,性能较高。
write.xlsx2(iris, file="data/iris.xlsx", sheetName="IRIS", append=FALSE) # append表示在指定的文件中添加一个新sheet